Redis分布式锁
前言
在单进程环境中,可以使用线程锁来解决资源竞争的问题,比如python提供的threading.Lock。但在分布式环境,就不能再使用多线程锁来处理多进程资源竞争问题了。这时我们需要自行实现自己的分布式锁,一般分布式锁有以下三种实现方式:
- 基于数据库
- 基于缓存,比如Redis
- 基于zookeeper
下面主要介绍基于Redis的分布式锁实现。
Redis单节点分布式锁
实现
客户端用下面指令获取锁:
x
SET resource_name my_random_value NX PX 30000my_random_value由客户端生成唯一标识符,目的是用于标识此次请求。在释放锁操作将用到。NX表示key不存在才能set成功PX 30000表示过期时间为30000毫秒
客户端用下面指令释放锁:
xxxxxxxxxxif redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1])else return 0end- ARGV[1]即执行命令时我们要传入的参数
my_random_value。
关于以上两个指令,我们需要注意几个问题:
第一,过期时间是必须要设置的。主要是为了避免客户端获取锁之后,因为进程崩溃或者网络问题使得锁得不到主动释放,从而导致死锁的情况。
第二,释放锁的操作需要使用Lua脚本来实现,这样子才能保证原子性。
第三,my_random_value是必要的,它可以避免下面的情况发生:
- 客户端1获取锁成功。
- 客户端1在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁。
主从复制导致的问题
在没有slave节点的时候,上面的实现是没有问题的。但实际工作中,我们往往使用master-slave的部署架构。当master节点宕机之后,会选择slave作为新的maste节点,由于Redis的主从复制是异步的,所以会导致如下问题:锁还没来得及同步到新的master,此时有另一个客户端去获取锁,因为没同步过来所以成功获取到了锁,导致同事存在两个客户端持有锁。
针对这个问题,Redis官方设计了Redlock算法,这就是下面部分要讲的。
Redlock算法
此算法要求有N个Master节点,这些节点之间互相是独立的。
获取锁的流程如下:
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串
my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。 - 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)
释放锁很简单,遍历N个节点,逐个释放。
针对Redlock算法的质疑声音
虽然Redis官方坚定认为redlock足够安全,但也有人提出质疑,比如有篇文章就提到了一个问题,地址为:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html, 这个问题可以用一张图来演示:
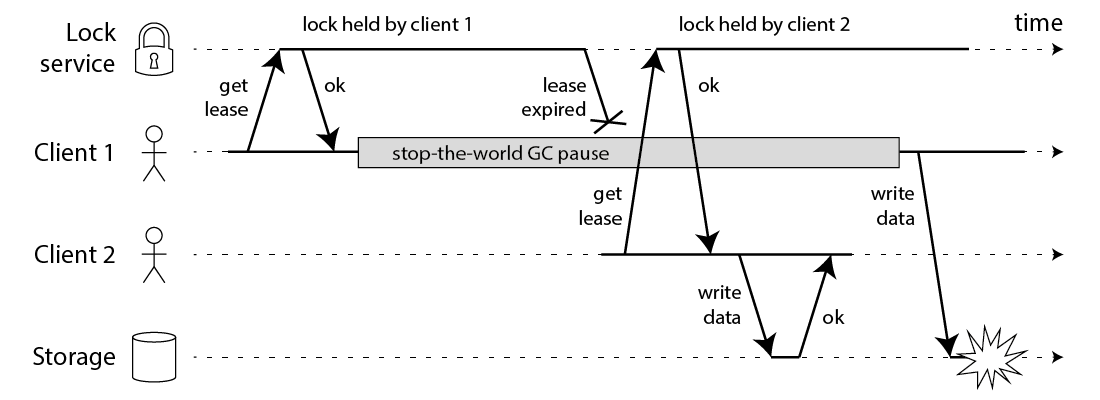
当client 1因为GC或者其他问题暂时假死,锁过期后,client 2获取到了锁,但突然client 1又活过来了,此时导致client 1和client 2同时持有锁,同时有write的权限。
当然这个问题,不仅仅在redlock算法存在,对于我们文章前面讲到的单节点分布式锁,同样存在。
文章最后,作者做了个结论:
- 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单Redis节点的锁方案就足够了,简单而且效率高。Redlock则是个过重的实现(heavyweight)。
- 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用Redlock。应该考虑类似Zookeeper的方案,或者支持事务的数据库。