一致性哈希算法的原理
目录
引言
在分布式系统中,有这么一个不得不面对的应用场景:
如何将m条数据或者m个请求,尽可能均匀地映射到n个数据库节点或者n台服务节点上。其中m是动态增长的,而且一般m远大于n。
本质上来讲,它就是个负载均衡问题,当然你可以说是分布式存储(缓存)问题。比如,将10000条数据,均匀地缓存到100个Redis节点中。解决此类问题,我们需要用到哈希算法或者一致性哈希算法。
哈希算法及其缺点
普通hash算法通过下面公式,求得数据对应存储的目标节点:
x
j = hash(key[i]) % n # 其中key[i]表示m条数据中,第i条数据的key。j为目标节点编号。但此种方法有个问题,如果节点数量变化(即n的值变了),那数据存储的位置也将随着改变。意味着当节点数量变化之后,几乎全部数据需要重新计算目标节点,并且需要重新移动数据。而一致性哈希就是为了解决普通哈希算法这个缺点而诞生的。
一致性哈希算法
跟普通哈希算法对节点数量n取余不同,一致性哈希是对取余,这就保证了,即使n变化,也不会影响公式的值。值得注意是,一致性哈希算法中,节点和数据都要经过公式求值,也就是说,节点和数据被映射到同一个空间里(这个空间有个点)。 而这个空间我们把它看做一个虚拟的环。
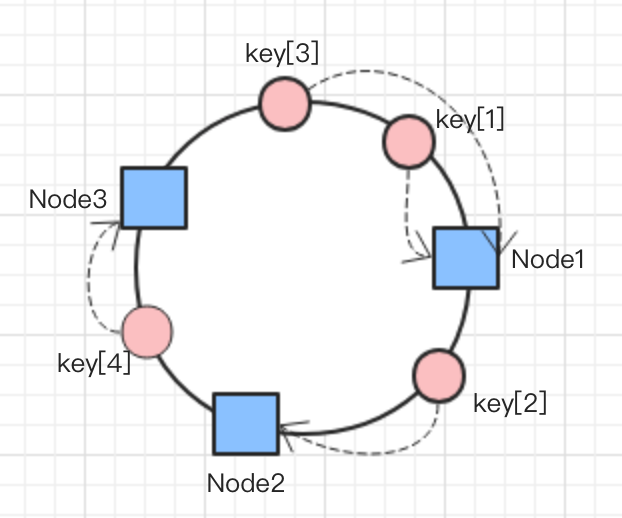
如图所示,有node1~node3总共3个节点被映射到环上,同样有key[1]~key[4]总共4条数据被映射到环上。使用如下的策略,决定数据映射到哪个节点上:从顺时针方向开始,离数据最近的节点即为选定的节点,例如key[4]离node3最近,所以key[4]这条数据将被分配到node3节点上。图中我们虚线箭头标识了所有key对应的node。
增加或删除节点
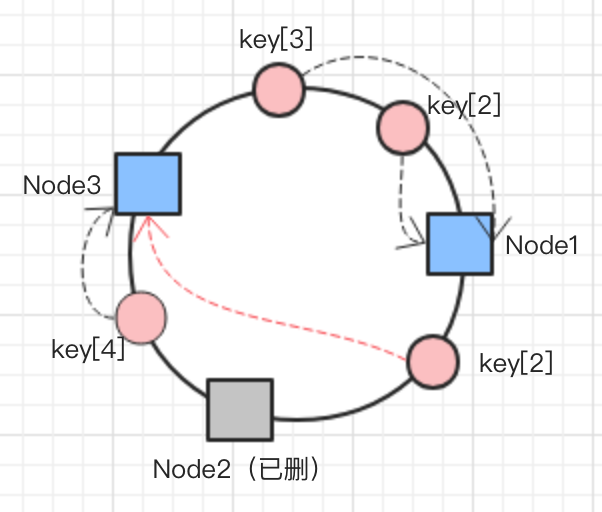
一致性哈希算法的优势在于,当增加或者删除节点时,对于大多数数据,保证所分配到的节点依然是原来那个,只有局部小部分数据需要迁移,将数据迁移率降到了最低。例如,假如图中的node2被删了,那只需要将key[2]移动到node3即可。
数据倾斜问题
当节点数量过少是,会出现节点分配不均的情况发生。
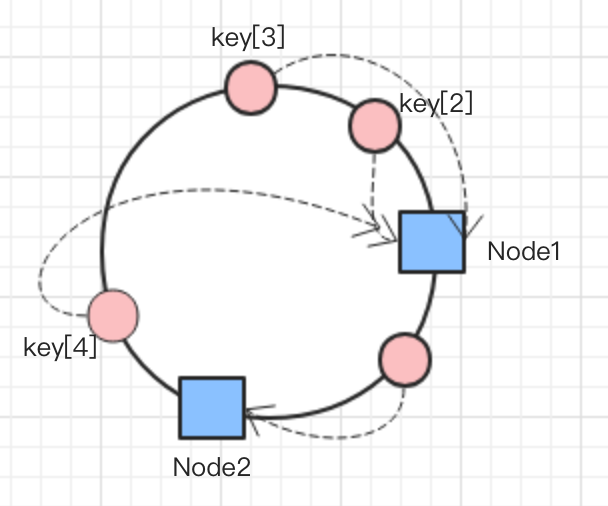
如图所示,大部分数据集中到了node1。为了解决这个问题,一致性hash算法引入了虚拟节点的概念。
改进-虚拟节点
为每个物理节点设置多个虚拟节点,一般设置32个,甚至更大。因为虚拟节点数量足够大,所以在环上的分布也更均匀,这就解决了数据倾斜问题。
当物理节点删除后,虚拟节点可以不动,而只要改变虚拟节点所代表的物理节点即可。