一种BI数据平台架构方案
最近厂里面新增了对订单数据分析的需求,如果在业务系统做,一方面可能会影响业务功能的正常运行,另一方面数据分析的性能也得不到保障,毕竟数据分析场景就应该用大数据处理相关的数据库和技术。考虑到以后相关的需求会越来越多,于是BI平台建设被提上了议程。
本文提供一种建设BI平台的一种可行性方案。
BI平台的职责
在做技术选型之前,必须先明确系统的职责,这样才能判断要选择的技术是不是能满足业务需求。
- 报表服务:生成、导出报表;报表订阅
- 实时图表展示:折线图、柱状图、饼图、地图、热力图...
- 实时业务数据监控&告警:比如异常订单的监控、库存预警...
- 数据挖掘&AI分析:销量预测、用户画像等
- 对外开放数据:暴露API给其他部门或者合作商
架构图
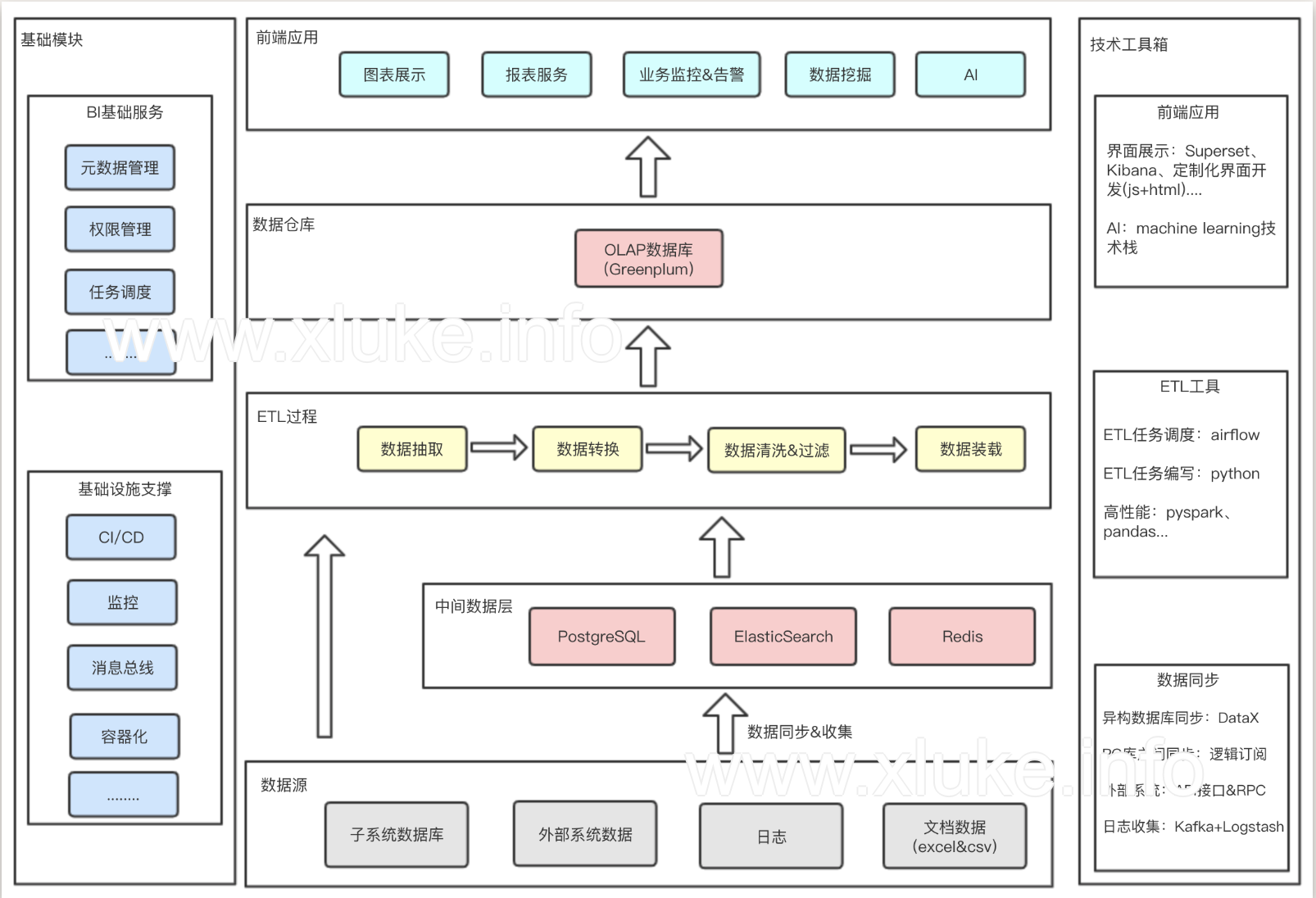
核心要素
数据源和数据同步
确定BI平台的数据源相当重要,因为它决定了要采用哪种数据收集方式。
数据源有:
- 日志
- 业务数据库
- 外部系统数据
- 文档数据
同步方式有:
- 数据库级别的同步:mysql的binglog;postgresql的逻辑订阅;或者阿里DataX。
- 日志收集:logstsh+kafka,走ELK那套流程
- 接口同步:使用http接口或者rpc的方式将数据同步到BI平台
数据仓库
传统的OLTP数据库(比如postgresql、mysql...),是不适合用在数据分析这种批量写入、查询次数多的场景。于是需要选择一款OLAP型的数据库,这里选择Greenplum,是因为Greenplum是基于postgresql引擎的一个数据库,而我们业务线上广泛使用了postgresql,对其比较熟悉。
当然个别需求,我们也会使用ElasticSearch和Postgresql,但主要的数据仓库还是Greenplum。
ETL过程
etl过程包括了数据清洗、过滤等操作,是一个BI系统必不可少的一个过程。市场上有很多现成的ETL工具可以利用,但这里我选择了自己写代码撸,主要是为了保持架构的简单和灵活,不想引入太多通用却无法定制的东西。
etl任务用手写代码实现,然后使用airflow任务调度系统管理和监控这些任务的执行。
前端展示
在前端开发人员不足的情况下,这里选择了使用开源的数据可视化工具。对比之后,最终选择superset,使用python编写,以后好定制。市场上也有其他类似的开源工具可供选择,可参考数据可视化的开源方案: Superset vs Redash vs Metabase。